
So your website isn’t as performant as you have been hoping….
Your insights scores are coming up short affecting SEO rankings or your end users are stuck in an endless ![]() as they wait to get content loaded in. You may want to reach the upper echelons of site speed but as you’re fiddling to try it just ends up feeling like a dance of plugging in various combinations of settings / plugins. You hope to eventually find the magic combination, but tick the wrong box and watch as the speed plummets even further down.
as they wait to get content loaded in. You may want to reach the upper echelons of site speed but as you’re fiddling to try it just ends up feeling like a dance of plugging in various combinations of settings / plugins. You hope to eventually find the magic combination, but tick the wrong box and watch as the speed plummets even further down.
One way to handle such issues is:
For those looking for a more practical, though admittedly less cathartic approach, google insights recommendations can be your friend…. but the recommendations are very detailed and are worded in way that makes them unintuitive without digging deeper into the underpinnings of how the web works.
That means you will still almost certainly require a developer to handle this kind of optimization… but even with the knowledge of how it all works, optimization is more of an art than a hard science as the needs of every site is unique. The code is too complex to determine how to balance all the various pieces at once. You need shortcuts. Ways to infer the underlying structure without reading every underlying bit of code. I’ll get to that in a bit, but first I’ll make a case for why caching and CDN’s should always be the last step in the optimization path, and why the techniques I’ll describe will get you further.
CDN’s / Caching when you think about it are really just end of the chain delivery techniques. They focus on getting you the data you need as fast as they can.
They are a catchalls that target issues covered by as as wide of range of sites/setups.
Another way of looking at it is they are built to get the data to you as fast as possible, but come with almost no knowledge of what that data is to actually prioritize things on a more granular level.
That’s where dev work comes in.
The untapped potential of async and defer
Often a developers first priority in making a site is getting things working. This is obvious, as a solution that doesn’t work isn’t a solution. To this end, many sites are built such that all the actual work / computation necessary to get things functioning as expected is done at the tail end of a site loading. This is so that everything the code wants to operate on is guaranteed to ready to go/available to be manipulated.
Since optimization is the last step, it’s also the one most susceptible to being forgotten or pushed in the interest of delivery. That’s beside the fact that the true issues of a slow site can require a detailed analysis to even properly track down/quantify. People can tell a site is slow for example, but as for how to speed a site up there’s often many solutions; it’s a more a matter of determining where to prioritize and how to balance the considerations that’s the hard part. In my opinion, one of the best places to start on the path to optimization is making use of async/defer tags on scripts which is often overlooked. To illustrate why, I’ll outline one of the most fundamental parts of how websites “work” which is often overlooked by asking a simple question.
How does a browser know what order you want to do things in?
Websites are composed of many files serving very different purposes. There’s the basic html which composes the bulk structure of the site, but separate from that is likely around 20 other files which control anything from styling to actual code on the page. If you want your site to look/act the same every time someone loads a page, than you need it to load/use all those files in a deterministic way; which is a fancy way of saying: the end result is guaranteed to be the same every time. This is accomplished by GUARANTEEING the order that things happen. How does a modern browser do this?
Well, it’s actually kind of simple: it does a line by line reading of the html. This might not seem like a big deal and is pretty obvious. “It just does things in the order you tell it!” but stay with me as things get funky pretty quick. The code you want a browser to execute in many cases is actually in an external file. That external file takes time to download. The time that files takes to download…. isn’t set in stone. Not only is it not set in stone, but it could take quite a while for any number of unforeseen reasons.
How does a browser handle this when it’s trying to make sure it does everything in the order you’ve been supplying the instructions? The answer is rather dumb. Super mega dumb actually.
Your $2000 multi-core computer capable of billions of calculations per second will go through the supplied html and when it sees a file in needs to download it will send a request to download the file and then…. WAIT. No, seriously…. it just sit’s there doing almost* nothing. Imagine how much work you’d get done in a day if you waited for a response from every email you sent out before moving onto the next task.
That should give you an idea of how much untapped potential there is to speed things up and is precisely where async/defer comes in.
SCRIPT FETCH EXECUTION HTML PARSING WAITING SCRIPT FETCH EXECUTION HTML PARSING WAITING SCRIPT FETCH EXECUTION HTML PARSING <script> <script async> <script defer>
So what determines the use of one over the other? Simple, if you need guaranteed order use defer, if not use async.
Wait? Defer guarantees order? Why not just use it all the time then? Well, if you tell your computer to just hold off on doing too many of these complex calculations to the very end… than you create a resource bottleneck. Your window will freeze and become unresponsive as it chugs through calculation after calculation. Looking at it a little differently: when you use async, you’re allowing for things to be a little more roughly spread out over time easing the cpu load at the cost of no longer guaranteeing order.
Rather annoyingly (from a debugging/developer standpoint) while the order isn’t guaranteed with async, it often looks like it is. This makes sense, as whatever order you ask for things may well be close to the order you get the responses. If you ever see an issue on a page that only seems to happen sometimes when it’s loaded, it’s an order of execution issue caused by the complex timings not quite lining up on an asynchronously executed script. Note that while this article has focused purely on asynchronous downloading to speed up site delivery, another consideration when coding is whether or not the thing you are trying to manipulate even exist yet. As an example. telling a browser to take a heading, a make it scroll across the page visually. If you don’t have that heading… whoops. Nothing happens.
There is multiple ways to handle a scenario like this:
- putting the code in the footer
- using deferral (which downloads early but executes at the end)
- adding a callback inside the code that tells it to execute once the page is loaded
These all have slightly different implications in terms of resources being spread out and impact on the site, so playing around is sometimes necessary to get the intended results. Also keep in mind that not all pieces are within your control as a developer. In particular, the use of a callback to guarantee something happens at a specific time can be baked into a library you are using which you can’t really change. This is one reason why choosing a library that is optimized for speed/lightweight can be crucial for site speed… but as a general rule, if you have a Java Script (JS) library (which is usually pretty heavy), download/queue it in as early as possible. Often this means creating an “object” in memory of said library as early as possible as well, not just getting the script itself. Note that having libraries ready early is important enough that browsers actually have a feature to signal if a script provided is a library. It looks like this:
<script as="module" scr=........Functionally, this is really like saying “this is a module/library. It’s probably gonna big/important with linked files, give it a higher priority to download/prime” and the leaves the complexity of deciding how to do that up to the browser.
If this is all starting to add up into “OMG, how the heck to balance all these considerations?”…. When using libraries that are potentially thousands of lines of code?…… YUP!
Making the complex look easy
So how do we balance all this?
Your first priority should be the “worst offenders”. Not all JS is built equal, and if you have a library that’s 150kb ask yourself if what you get out the library matches what you actually need. Note there’s tools nowadays that can tell you how much of a given library is in use and it’s impact:
https://developer.chrome.com/docs/devtools/coverage/
https://developer.chrome.com/docs/devtools/evaluate-performance/
Coverage tells you what percentage of a given codebase is in use (example, only 30% of a given library is used on your site)
Performance let’s you see how “heavy” the code is in it’s calculations (example, it take 200ms of complex calls to do what it needs to).
The concept of Coverage brings up a technique called code stripping, where we scan a site and remove unused code, but that’s a topic unto itself as the implementation of that technique varies wildly depending on platform. The larger point though is to assess what is inefficient to the task it’s doing and if you really need everything it does. When you find you have a large library that you barely use on a given site, consider finding lightweight alternatives that do the same thing. Usually this comes at the cost of changes in markup or code, but luckily many libraries take inspiration from each other and the markup tends to be similar enough that even a search and replace is enough. With this, you can make make code changes to the code as needed.
Note this technique is really simple when working on files locally.
Your second priority should focus on delivery. Generally speaking I prefer to async all code I can and then test what features have broken. This allows me to find code that needs synchronous loading without digging into the intricacies of said code. Then, the list of code that needs some form of synchronicity is gone through and deferred under the hope it doesn’t cause a bottleneck. The order of the deferred scripts at this point is important so I make sure things are in the order I need. One thing to note though is that libraries themselves will be built with the very real possibility of event handlers inside themselves, which means you can’t say for sure all the code in a given library follows the order you expect by deferring. This is where testing across browsers to make sure consistent loading happens.
Why different browsers? Well, even though we have large scale ideas on the order of excecutions of things, the fact is each browser has it’s own implementation of more detailed pieces.
Here is an example of a rendering stack for example in a webkit based browser.
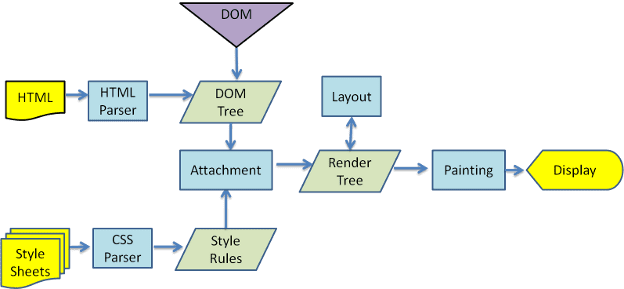
Chrome has it’s own process that though largely similar has some differences that make exact order of execution on a more granular level difficult to achieve. This makes really specific event firing a bit of a headache and another reason to try and stick to higher level optimizations that are more cross compatible. Generally speaking, there’s 2 common events with code we can attach to delay the execution of code:
document.addEventListener('DOMContentLoaded'
window.addEventListener('load'......The dom content loaded is essentially a notice all the HTML was supplied (essentially…. </html> was detected so there shouldn’t be anything else). The window load event is: all externally linked files and images have been downloaded and loaded. Note that “DOMContentLoaded” is essentially when deferred scripts execute already, so using it as a strategy to maintain order doesn’t really gain you anything over, just deferring a script (especially since deferred scripts execute in order supplied in the HTML, where as code made to execute on a “DOMContentLoaded” event in general isn’t guaranteed any order relative to other code wrapped in a “DOMContentLoaded” event handler). If you are using it as a strategy and it works to enforce order, it’s only because the parts it relies on have already happened.
Wrapping it all up
Using these techniques you can optimize your site without getting into the nitty gritty as much as you rely on practical testing to cover consistent performance. This leaves a small possibility where things don’t fire as expected in unique permutations you hadn’t considered (example browser render stack differences, odd network errors where a particular file takes a long time to load, etc.)…. but that’s often the reality of developing a large scale project with many disparate pieces brought together. Some setups are more vulnerable than others (overloaded servers where file delivery is a little more all over for example), but in general using the techniques I’ve described above can get you very far in increasing your sites speed while still getting consistent performance.
For further optimizations, it really depends on the platform you are building to, but techniques like server side caching if your TTFB score is low, client side caching if your site uses resources across pages, loading in js/css only on pages that need them, minification, lazy loading images and srcsets (a fancy way to get a browser to download a movie, image or audio file in the best format it supports for easy legacy support with modern file formats).
Hopefully you’ve found this article helpful and intuitive.